Kiat bekerja sebagai rekrutan data pertama: Bagian I
Bagian pertama dari dua tulisan. Bagian ini membahas perkara teknis ketika bekerja sebagai rekrutan data pertama.
Banyak organisasi (bisnis) bercita-cita menjadi organisasi yang terinformasikan (informed), maksudnya sanggup menyediakan data yang bisa diakses semua orang dalam organisasi untuk bisa membuat keputusan dengan tepat. Bayangkan Anda adalah rekrutan data pertama di organisasi dengan cita-cita seperti itu. Anda mendapat titah, “Pecahkan masalah-masalah hari ini sambil bersiap untuk masa depan.”
Tulisan ini menyuguhkan kiat untuk melakoni kerja sebagai rekrutan data pertama. Rencananya, akan ada dua tulisan. Pertama, membahas bagian teknis dari pekerjaan data, dan kedua, bagian politis. Kebanyakan yang ditulis di sini berasal dari pengalaman saya sendiri, yang sekarang sedang menjadi rekrutan data pertama.
Struktur tim data
Di awal bekerja dulu, saya berada di tim atau organisasi data berukuran kecil-sedang. Awalnya ada dua orang analis data. Kemudian menjadi tiga orang analis data, kemudian menjadi satu orang dan satu paruh waktu. Struktur tim data memakai model terpusat (centralized). Model terpusat berarti satu tim data mengatasi kebutuhan nyaris semua tim lain, mulai dari tim pemasaran, penjualan, produk, konten, dan finansial. Keuntungan praktis berada dalam tim data dengan model terpusat adalah punya kesempatan mengakrabi dan mengerjakan data dari banyak bidang.
Struktur lain adalah tim data terdistribusi (distributed/embedded). Analis disebar ke beberapa tim yang butuh mengolah data. Analis bisa ditempatkan di satu tim saja, atau dua. Saya belum pernah berada di tim data terdistribusi, sehingga tak bisa bercerita banyak. Tapi saya bisa bayangkan keuntungan praktisnya. Praktisi data yang bekerja untuk satu-dua tim bisa lebih fokus, lebih cepat mengeksekusi permintaan data, dan berpotensi punya pengetahuan lebih dalam di bidang tertentu.
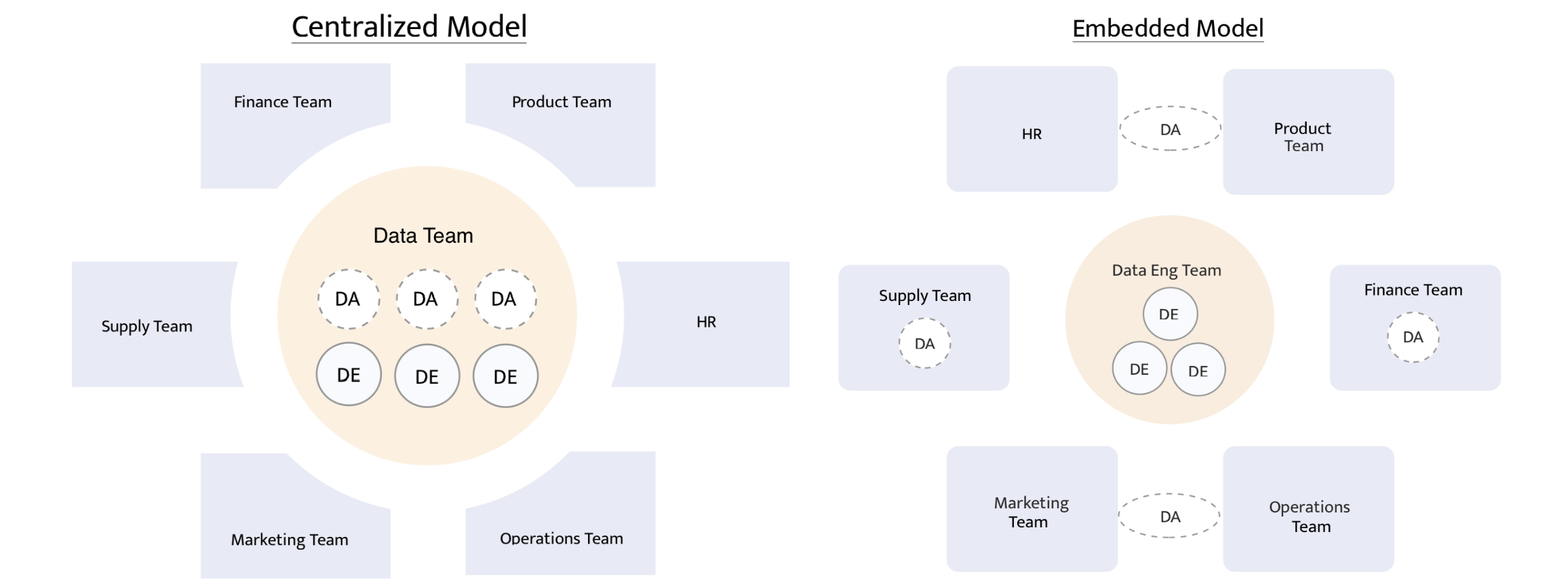 Tim data model terpusat dan terdistribusi. Sumber: How should our company structure our data team?
Tim data model terpusat dan terdistribusi. Sumber: How should our company structure our data team?
Struktur mana yang dipakai biasanya bergantung pada skala organisasi dan bagaimana masing-masing organisasi beroperasi. Ada juga tim data berisi satu orang yang menopang lebih dari 200 orang.
⚠️ Jika Anda adalah rekrutan data pertama, besar kemungkinan Anda mesti menopang kebutuhan data nyaris semua tim lain.
Tahapan pengorganisasian data
Saya baru selesai membaca sebuah buku berjudul The Informed Company. Di buku itu, Dave Fowler dan Matt David menyebut ada empat tahapan pengorganisasian data: Source, Lake, Warehouse, dan Mart. Di mana posisi sebuah organisasi dalam keempat tahap itu bergantung pada sumber daya, ukuran, dan kebutuhan data si organisasi. Buku itu bilang, selama organisasi bisa mendapatkan wawasan (insight) yang dibutuhkan, maka tak perlu beranjak ke tahap selanjutnya.
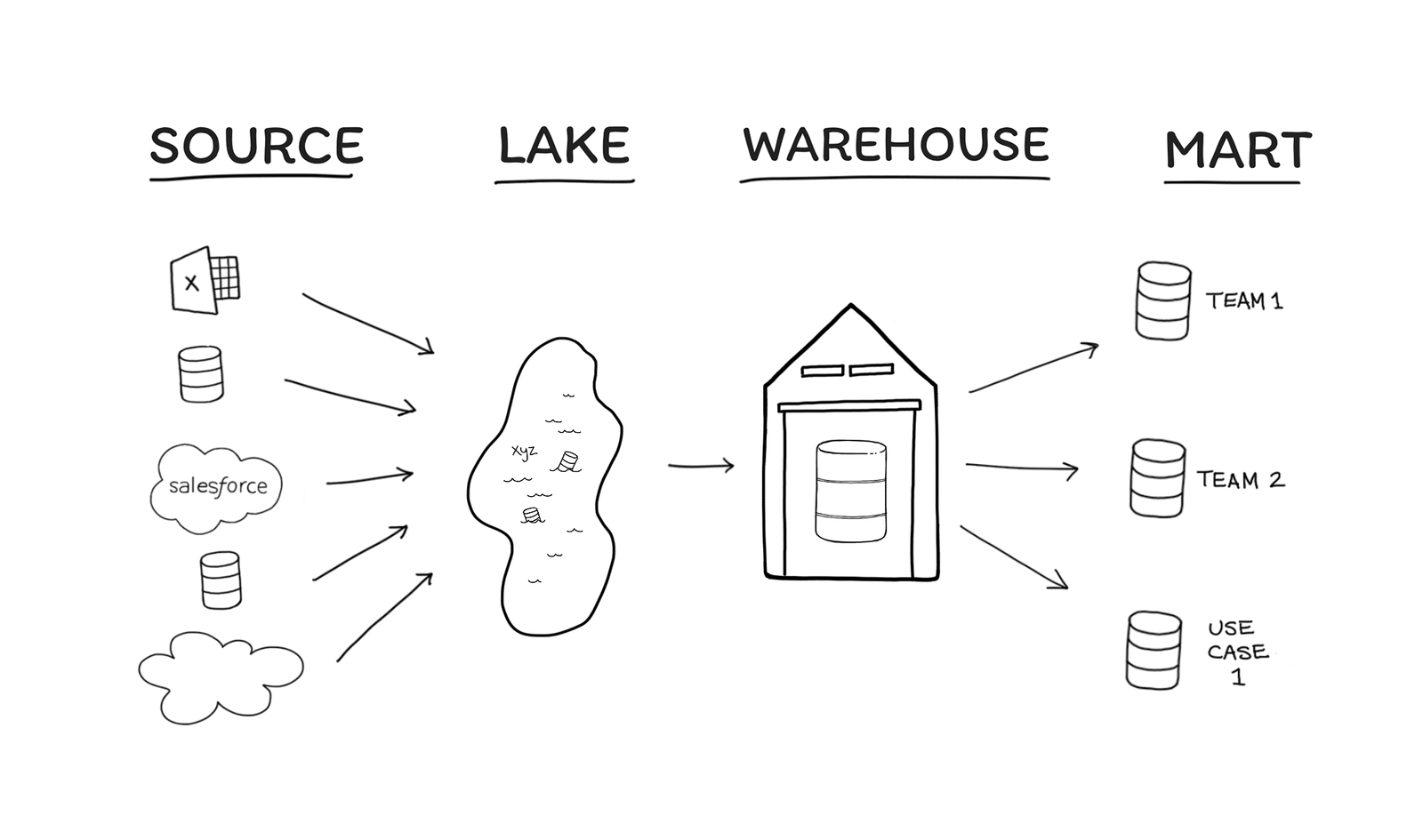 The 4 Stages of Agile Data Organization. Sumber: The Informed Company
The 4 Stages of Agile Data Organization. Sumber: The Informed Company
- Tahap pertama adalah Source atau Sumber. Yakni ketika organisasi bisa memperoleh wawasan dengan cara mengambil dan mengolah data secara langsung dari Sumber.
- Tahap kedua adalah Lake atau Danau. Tak jarang organisasi memerlukan data dari banyak Sumber. Data dari berbagai sumber dikumpulkan dalam satu tempat (misal, data dari media sosial, pangkalan data operasional, peranti pemasaran, pelacak peristiwa, dll). Alasan utama untuk beranjak ke tahap ini adalah kebutuhan untuk menjahit data dari berbagai sumber tersebut agar bisa ditayangkan oleh peranti Business Intelligence (BI). Ini memudahkan pekerjaan tim data karena tak perlu lagi berpindah dari satu Sumber ke Sumber lain dan mengunduh datanya.
- Tahap ketiga adalah Warehouse atau Gudang. Tahap ini diperlukan ketika data dalam Danau sudah kepalang ruwet untuk dipahami atau dikueri. Dalam praktik data kontemporer, data di danau data biasanya disimpan begitu saja. Tak melalui proses transformasi. Gudang adalah upaya untuk membuatnya lebih terorganisasikan lewat berbagai transformasi/pemodelan data.
- Tahap keempat adalah Mart atau Pasar. Data di Gudang bisa terakumulasi hingga mencapai ratusan tabel. Pengguna bisa kewalahan mencari data tertentu. Dalam tahap Pasar, pemodelan data dilakukan untuk mendistribusikan data sesuai kebutuhan atau sesuai bidang operasional.
⚠️ Jika Anda merupakan rekrutan pertama, besar kemungkinan organisasi Anda sedang berada pada tahap Sumber, tahap ideal untuk organisasi baru. Ciri-ciri tahap sumber adalah hanya ada beberapa orang yang perlu bekerja dengan data, dan kebutuhan data serta sumber data yang tersedia masih sedikit.
Menjadi praktisi data tanpa memahami tahapan data ini seperti… menjadi seorang kiri tanpa pernah belajar Marxisme-Leninisme. Bercita-cita mewujudkan revolusi sosialis tanpa mepelajari cara paling tepat untuk mewujudkannya.
Pertama kali saya bekerja, tim data hanya berisi dua orang. Saya dan seorang rekan yang lebih senior. Kami bukan sarjana Teknik Informatika. Tak pernah mendapat ilmu pengelolaan pangkalan/pergudangan data. Saya dulu siswa sekolah kejuruan jurusan Rekayasa Perangkat Lunak. Tetapi pelajaran tentang basis data hanya sampai pada bagaimana membangunnya untuk tujuan operasional atau pembangunan aplikasi, bukan untuk tujuan analitik.
Bertahun-tahun kami berdua seperti hidup dalam cerita rakyat praktisi data (80% waktu habis membersihkan data). Saya berada dalam pusaran tahap Sumber cukup lama karena tak punya ide bahwa tahap selanjutnya ada.
Menjelang saya keluar dari organisasi itu, saya mematerialkan beberapa tabel hasil agregasi secara inkremental untuk mempercepat dan menghemat biaya kueri. Kueri-kueri per kuartal atau per tahun yang biaya eksekusinya bisa mencapai sekian dolar kini menjadi sekian sen. Tapi saat itu pun, konsep tentang tahapan data belum benar-benar saya pahami, meski sampai tahap tertentu saya telah mempraktikkannya: bahwa data tak melulu harus diambil dari Sumber, dan kita bisa membangun berbagai model dari model mentah atau kasar yang telah ada.
Kita bisa berkembang ketika dihadapkan pada masalah. Tapi untuk apa semua kesusahan itu? Waktu dan biaya yang saya habiskan untuk itu terlalu mahal. Andai saja buku ini terbit lebih awal, atau saya membaca buku macam ini, di awal bekerja dulu.
Menjadi rekrutan data pertama
Sekarang, saya harap Anda bisa memahami bahwa tulisan ini berangkat dari asumsi dan pengalaman seorang praktisi data yang hanya pernah berada di tim data kecil yang terpusat, belum lama mengenal tentang tahap data dan konsep-konsep di dalamnya, dan sekaligus sedang menjadi rekrutan data pertama.
Sebelum lanjut, mari kembali mengingat dua hal yang perlu diperhatikan rekrutan data pertama:
- Anda mesti menopang kebutuhan data semua orang.
- Organisasi Anda sedang berada pada tahap Sumber.
Jika Anda sebelumnya berada di organisasi yang lebih dewasa, di tahap yang lebih maju, apalagi pernah Anda bergabung di tim yang “matang”, mungkin Anda tak terlalu terbiasa mengolah data langsung dari Sumber. Mungkin Anda lebih sering menggunakan data dari Pasar atau Gudang, yang secara model data jauh lebih sederhana karena telah mengalami berbagai transformasi. Atau, Anda sebelumnya ada di tim data terdistribusi, sehingga tak biasa bekerja dengan data dari bidang lain. Padahal, tantangan teknis sebagai rekrutan data pertama adalah mempelajari dan berinteraksi di level Sumber, dan bekerja untuk semua bidang.
Dalam organisasi, ada beberapa sumber data yang umum dipakai, misalnya:
- Operasional: Sumber data dari pangkalan data yang dipakai oleh produk/aplikasi untuk beroperasi.
- Media sosial: TikTok Analytics, Twitter Analytics, FB Page Insights, IG Insights, YouTube.
- Periklanan: FB Ads Manager, Google Ads.
- Atribusi: Adjust, Branch, AppsFlyer.
- Transaksi: Stripe, Xendit, Paddle.
- Pelacak peristiwa: Google Analytics, Rudderstack, CleverTap, Mixpanel, Amplitude, Snowplow, Segment.
Mari kita bahas beberapa.
Data operasional biasanya dirancang dalam Bentuk Normal Ketiga (3NF), yang disimpan di dalam Sistem Manajemen Basis Data Relasional (RDBMS) yang optimal untuk kerja-kerja transaksional (memanggil, menambah & menghapus baris tertentu). RDBMS yang dipakai biasanya MySQL atau PostgreSQL. Konsekuensi praktis bagi rekrutan data pertama yang bekerja dengan Bentuk Normal Ketiga adalah pengambilan data yang kerap kali lebih rumit—bisa dari hasil operasi JOIN terhadap 5 tabel atau lebih sekaligus, misalnya. Selain itu, kueri harus dibangun dengan sangat memperhatikan performa, karena basis data yang dipakai tidak dibuat untuk kerja-kerja analitik. Kemudian, hal lain yang juga penting untuk diperhatikan adalah jangan mengeksekusi kueri terhadap basis data yang dipakai oleh aplikasi secara langsung, melainkan terhadap basis data replika dari basis data aplikasi.
Data yang dipakai oleh tim pemasaran biasanya berasal dari media sosial, platform periklanan, dan atribusi. Ada beberapa catatan bagi rekrutan data pertama. Pertama adalah mempelajari bagaimana mengoperasikan dasbor di masing-masing platform. Kedua, memahami bagaimana data dihasilkan dan metrik apa saja yang disediakan. Ketiga adalah mempelajari platform analitik lain yang fokus terhadap hal tersebut. Keempat adalah mempelajari bagaimana rekan tim bekerja dengan data.
Untuk memahami bagaimana data dihasilkan dan metrik apa saja yang tersedia, kita bisa membaca dokumentasi dasbor dari masing-masing platform dan juga dokumentasi API mereka. Mempelajari berbagaiplatform analitik lain yang berhubungan (misal, Buffer, Iconosquare, Socialbakers) juga bisa membantu mengenal metrik lain yang mungkin berguna untuk analisa atau pelaporan. Bisa juga pelajari platform layanan koneksi data pihak ketiga seperti Stitch, Fivetran, atau Supermetrics. Mempelajari produk dan dokumentasi mereka akan banyak membantu ketika tiba saatnya untuk beranjak dari tahap Sumber. Mempelajari bagaimana rekan tim bekerja dengan data ialah memahami bagaimana mereka memodelkan Spreadsheet mereka, kapan melakukan laporan, apa metrik yang penting menurut mereka, dll.
Selain data-data yang sudah tersedia, organisasi juga akan butuh data lain. Salah satunya, pelacakan peristiwa. Rekrutan data pertama juga mesti merancang dan memutuskan platform apa yang akan dipakai. Penting untuk mempelajari bagaimana merancang pelacakan peristiwa. Lagi-lagi, dokumentasi dari semua platform pelacak peristiwa adalah tempat belajar yang baik. Saya punya pandangan terkait pelacakan peristiwa ini, kapan-kapan akan saya buatkan tulisan tersendiri.
Menjadi rekrutan data pertama bukan hal gampang. Setidaknya ada dua tugas yang diemban: 1) pecahkan masalah hari ini, 2) bersiap untuk masa depan.
Pecahkan masalah hari ini, bagi rekrutan data pertama, adalah tentang menghasilkan wawasan (insight generation) dalam waktu secepat mungkin.
Saya berikan kasus sederhana sebagai berikut.
Anda mungkin berpengalaman dengan penyimpanan data awan seperti BigQuery, Snowflake, Azure, atau Redshift dan bertanya-tanya bukankah data operasional mestinya direplikasi dan diakses dari situ? Dalam kasus ini, jawabannya adalah belum tentu. Rekrutan data pertama perlu memberikan wawasan data secepat mungkin kepada tim. Tak masalah menghubungkan data replika di basis data transaksional langsung ke platform BI untuk mencapai wawasan dengan cepat.
Satu lagi contoh kasus sederhana.
Bayangkan organisasi Anda bekerja sama dengan Ad Network untuk memasang iklan dengan tujuan menambah jumlah instal aplikasi. Seorang analis diminta membantu tim pemasaran untuk menganalisis kanal Ad Network mana saja yang memiliki performa bagus, dalam arti murah, volume instal besar, tingkat retensi tinggi. Ketika analisis bisa dihasilkan dengan mengunduh file .csv secara manual dari Analytics & AppsFlyer, kemudian diolah di Spreadsheet untuk menentukan kanal mana yang perlu dipertahankan dan dihentikan, maka itulah yang mesti lebih dulu dilakukan. Tak perlu menunggu Danau atau Gudang yang menyatukan berbagai sumber data itu mewujud.
Kata kuncinya adalah menjadi gesit.
Lalu bagaimana dengan persiapan masa depan?
Sembari membuat berbagai laporan, dasbor, dan wawasan langsung dari sumber data, saat itu juga rekrutan data pertama juga mesti merancang bagaimana organisasi bisa dibawa beranjak ke tahap selanjutnya. Keduanya mesti dilakukan secara simultan.
Bersiap untuk masa depan berarti menentukan platform BI, pelacak peristiwa, penyimpanan data awan, peranti dan strategi untuk mengekstraksi dan memuat data ke Gudang, juga model Gudang yang akan dipakai. Dan tentu saja, menentukan kapan saat yang tepat untuk mulai beranjak ke tahap selanjutnya.
Terdengar lebih seperti tugas seorang insinyur data ketimbang analis data? Memang. Ini juga konsekuensi praktis sebagai rekrutan data pertama. Dan memang sekaranglah saat yang tepat untuk juga mempelajari dan mengamalkan apa yang para insinyur data lakukan.
Ada beberapa buku yang bisa dibaca untuk membantu Anda melalui semua itu:
- The Analytics Setup Guidebook
- The Informed Company
- The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd Edition
- Star Schema The Complete Reference
- Fundamentals of Data Engineering: Plan and Build Robust Data Systems
Menjadi rekrutan data pertama bukan hal gampang. Dan ini hanya membahas perkara teknis. Selanjutnya, saya akan membahas bagian politis.